System architectures
When discussing system architectures, in the context of this book we're more specifically talking about system administration, servers and their design and management.
A standard and fairly typical architecture includes redundant systems at all layers. There will be redundant application servers, databases, file servers, caches, proxies, and more. It's not unusual to see multiple systems on the same physical machine (ex: an in-memory cache on the same machine as the app server), but as the company's needs grow, it is sometimes necessary to move systems to dedicated machines.
The proliferation of containers and virtual machines has made this even easier, as it's now possible to quickly move workloads to different locations with a single command. This means it's even easier to homogenize the hardware and deploy machines with identical physical specs, regardless of what tasks they'll actually be running.
There used to be an exception to this regarding databases. Those typically benefited from large RAID arrays (RAID-5) with and high-end spinning drives, but nowadays with hyper-fast and relatively cheap SSD/NVMe drives, alternative "nosql" and "document" databases, and easy access to gobs of RAM, it's totally plausible to spec a database identically as a file or app server. In that case, heavier reliance is placed on database replication rather than "drive failure mitigation" (through RAID).
As an old-school sysadmin, I still sometimes lean towards RAID, but it's also something which has caused me great pain over the years (slow rebuilds, corruption, cascading failures). With replication to active servers, you're switching from the potentially high cost of extended downtime, to the often reasonable cost of additional hardware.
Below I provide an example of a standard system architecture within a single rack:
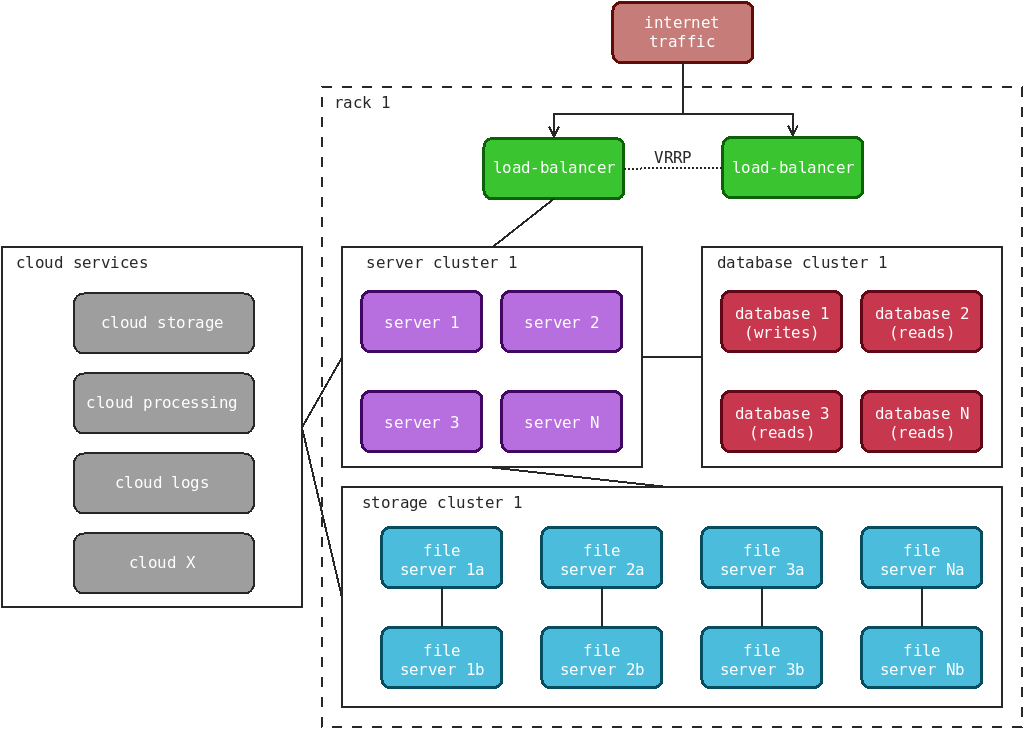
The first thing you might notice are the cloud services outside the rack. I could dedicate an entire page (or book) to that, but I'll keep it short by mentioning that all the hardware systems displayed above can be available in the cloud instead. It's an expensive alternative, but there are advantages for certain workloads.
In the past, I would have deployed a pair of load-balancers in active-passive mode (where one sits there quietly, doing nothing most of the time), but I find that quite wasteful of resources. I prefer to have them all handling requests actively. In many cases a reverse proxy such as HAProxy can serve static and cached assets, and even some dynamic content thanks to builtin scripting languages such as Lua. That can help offload tasks early and prevent certain requests from reaching the application servers.
The above diagram is not definitive, and you should expect it to vary between different awesome companies.
As a final note, it is also very common for awesome companies to have separate staging and production environments where code and applications are deployed. The staging environment allows for testing things without affecting production users, databases, etc. Some companies may even have a beta environment where an entirely different code path is used, giving select users early access to features which haven't been deployed to everyone else.